Download this notebook from SiddharthaPradhan/stanbkt
Multi BKT Example Using Simulated Grouped Data#
This walkthrough mirrors the simple example (02_simple_example.ipynb) but uses grouped data and MultiBKT.
In this notebook, we will:
Simulate grouped BKT data with group- and KC-specific parameters.
Instantiate and fit a
MultiBKTmodel.Generate Numba-accelerated point-estimate predictions (
predictandpredict_smoothed).
This example stops after fitting and Numba-based predictions.
Simulate Grouped BKT Data#
We simulate students from multiple groups. Each group can have different BKT parameters, and in this example, parameters also vary across KCs.
[1]:
from stanbkt.utils import sim_grouped_BKT
[2]:
N_GROUPS = 3
N_KCS = 2
# rows=groups, cols=KCs
bkt_params = {
"prior": [[0.20, 0.10], [0.35, 0.25], [0.50, 0.40]],
"learn": [[0.03, 0.06], [0.05, 0.08], [0.08, 0.10]],
"forget": [[0.01, 0.01], [0.02, 0.02], [0.02, 0.03]],
"guess": [[0.25, 0.20], [0.20, 0.15], [0.15, 0.10]],
"slip": [[0.10, 0.08], [0.08, 0.07], [0.06, 0.05]],
}
[3]:
data_df = sim_grouped_BKT(
n_students=60,
n_problems=80,
n_kcs=N_KCS,
n_groups=N_GROUPS,
frac=0.85,
rng_seed=12345,
**bkt_params,
)
[4]:
data_df.head(10)
[4]:
| student_id | problem_id | correct | timestamp | kc_id | group_id | |
|---|---|---|---|---|---|---|
| 0 | stu_0 | prob_0 | 0 | 2024-01-01 00:00:00 | kc_1 | group_0 |
| 1 | stu_0 | prob_1 | 1 | 2024-01-01 00:01:00 | kc_0 | group_0 |
| 2 | stu_0 | prob_2 | 0 | 2024-01-01 00:02:00 | kc_1 | group_0 |
| 3 | stu_0 | prob_3 | 1 | 2024-01-01 00:03:00 | kc_0 | group_0 |
| 4 | stu_0 | prob_4 | 1 | 2024-01-01 00:04:00 | kc_0 | group_0 |
| 5 | stu_0 | prob_6 | 0 | 2024-01-01 00:06:00 | kc_1 | group_0 |
| 6 | stu_0 | prob_7 | 1 | 2024-01-01 00:07:00 | kc_1 | group_0 |
| 7 | stu_0 | prob_8 | 1 | 2024-01-01 00:08:00 | kc_1 | group_0 |
| 8 | stu_0 | prob_9 | 1 | 2024-01-01 00:09:00 | kc_0 | group_0 |
| 9 | stu_0 | prob_10 | 0 | 2024-01-01 00:10:00 | kc_1 | group_0 |
[5]:
data_df[["group_id", "kc_id"]].value_counts().sort_index()
[5]:
group_id kc_id
group_0 kc_0 658
kc_1 700
group_1 kc_0 663
kc_1 705
group_2 kc_0 656
kc_1 698
Name: count, dtype: int64
MultiBKT expects long-format data including the standard columns (student_id, problem_id, correct, timestamp, kc_id) plus group_id.
[6]:
required_cols = [
"student_id",
"problem_id",
"correct",
"timestamp",
"kc_id",
"group_id",
]
data_df[required_cols].head(5)
[6]:
| student_id | problem_id | correct | timestamp | kc_id | group_id | |
|---|---|---|---|---|---|---|
| 0 | stu_0 | prob_0 | 0 | 2024-01-01 00:00:00 | kc_1 | group_0 |
| 1 | stu_0 | prob_1 | 1 | 2024-01-01 00:01:00 | kc_0 | group_0 |
| 2 | stu_0 | prob_2 | 0 | 2024-01-01 00:02:00 | kc_1 | group_0 |
| 3 | stu_0 | prob_3 | 1 | 2024-01-01 00:03:00 | kc_0 | group_0 |
| 4 | stu_0 | prob_4 | 1 | 2024-01-01 00:04:00 | kc_0 | group_0 |
Instantiate and fit MultiBKT#
As in the simple example, Stan code is compiled lazily on the first fit(...) call and cached for reuse.
[7]:
from stanbkt.models import MultiBKT
from stanbkt.fits import FitMethod, MCMCFitOptions
from stanbkt.models import MultiPriors
from stanbkt.utils import VerbosityLevel
[8]:
model = MultiBKT(
fit_method=FitMethod.MCMC,
verbose=VerbosityLevel.WARN,
)
fit_opts = MCMCFitOptions(
seed=1234,
iter_warmup=500,
iter_sampling=500,
)
priors = MultiPriors(use_defaults=True) # using default priors for all groups and KCs
Unlike the previous example (02_simple_example.ipynb), we will pass the entire DataFrame containing both KCs.
[9]:
model.fit(data_df, stan_fit_options=fit_opts, priors=priors)
17:00:36 - cmdstanpy - INFO - CmdStan start processing
17:00:47 - cmdstanpy - INFO - CmdStan done processing.
17:00:47 - cmdstanpy - INFO - CmdStan start processing
17:00:55 - cmdstanpy - INFO - CmdStan done processing.
[9]:
MultiBKT(fit_method=<FitMethod.MCMC: 'mcmc'>, verbose=<VerbosityLevel.WARN: 1>, is_fitted=True)
Generate a summary of the parameters’ posterior distributions.
[10]:
summary = model.summary()
summary
[10]:
| Mean | MCSE | StdDev | MAD | 2.5% | 50% | 97.5% | ESS_bulk | ESS_tail | R_hat | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| kc_id | parameter | ||||||||||
| kc_1 | lp__ | -921.694000 | 0.118435 | 3.010790 | 2.884400 | -928.645000 | -921.360000 | -916.903000 | 660.542 | 843.480 | 1.002110 |
| logit_pi_know_group[1] | -3.428550 | 0.085990 | 2.119080 | 1.248890 | -9.653540 | -2.811810 | -1.208540 | 1028.270 | 871.355 | 1.008320 | |
| logit_pi_know_group[2] | -0.953987 | 0.015008 | 0.626301 | 0.585673 | -2.271920 | -0.910853 | 0.165178 | 2127.500 | 1143.810 | 1.001320 | |
| logit_pi_know_group[3] | 0.063329 | 0.009998 | 0.541030 | 0.517822 | -1.026090 | 0.077880 | 1.113430 | 2983.860 | 1291.860 | 0.999119 | |
| logit_learn_group[1] | -2.610510 | 0.004827 | 0.250038 | 0.254466 | -3.126990 | -2.605160 | -2.150770 | 2962.300 | 1118.880 | 1.001850 | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| kc_0 | guess[2] | 0.206578 | 0.000706 | 0.035417 | 0.036829 | 0.141762 | 0.205580 | 0.279148 | 2559.340 | 1405.850 | 1.003210 |
| guess[3] | 0.148244 | 0.000900 | 0.039277 | 0.039619 | 0.079686 | 0.146121 | 0.233238 | 1955.870 | 1367.580 | 1.001490 | |
| slip[1] | 0.096202 | 0.000450 | 0.019514 | 0.018577 | 0.060655 | 0.095115 | 0.138666 | 1905.790 | 1533.050 | 1.002140 | |
| slip[2] | 0.048679 | 0.000269 | 0.012363 | 0.012165 | 0.027220 | 0.047605 | 0.075275 | 2159.430 | 1354.460 | 1.000900 | |
| slip[3] | 0.039134 | 0.000215 | 0.010497 | 0.010506 | 0.020468 | 0.038814 | 0.061320 | 2326.940 | 1208.900 | 1.001970 |
62 rows × 10 columns
[11]:
summary.loc["kc_0"] # summary for kc_0
[11]:
| Mean | MCSE | StdDev | MAD | 2.5% | 50% | 97.5% | ESS_bulk | ESS_tail | R_hat | |
|---|---|---|---|---|---|---|---|---|---|---|
| parameter | ||||||||||
| lp__ | -837.621000 | 0.108199 | 2.998410 | 2.808790 | -844.811000 | -837.255000 | -832.962000 | 800.308 | 1268.890 | 1.002780 |
| logit_pi_know_group[1] | -1.186370 | 0.016435 | 0.665201 | 0.602940 | -2.679060 | -1.115120 | -0.057710 | 1958.970 | 1067.480 | 1.003470 |
| logit_pi_know_group[2] | 0.612810 | 0.012302 | 0.562335 | 0.570284 | -0.454810 | 0.600089 | 1.745280 | 2128.260 | 1473.040 | 0.999152 |
| logit_pi_know_group[3] | 1.053900 | 0.014190 | 0.630915 | 0.560652 | -0.109400 | 1.015180 | 2.427780 | 2303.210 | 1122.930 | 1.001530 |
| logit_learn_group[1] | -3.303280 | 0.008623 | 0.383281 | 0.364401 | -4.125830 | -3.265930 | -2.636570 | 2149.770 | 1240.310 | 0.999253 |
| logit_learn_group[2] | -2.791580 | 0.008285 | 0.382229 | 0.385587 | -3.613330 | -2.774590 | -2.097270 | 2205.470 | 1401.090 | 1.004720 |
| logit_learn_group[3] | -2.138990 | 0.007243 | 0.320278 | 0.303473 | -2.830860 | -2.117300 | -1.555850 | 2049.870 | 1156.790 | 1.002120 |
| logit_forget_group[1] | -5.545130 | 0.058078 | 1.518500 | 1.055960 | -10.029100 | -5.232840 | -3.670290 | 1321.660 | 575.351 | 1.004160 |
| logit_forget_group[2] | -3.417570 | 0.006945 | 0.331542 | 0.317573 | -4.118930 | -3.394710 | -2.817380 | 2410.420 | 1507.380 | 0.999805 |
| logit_forget_group[3] | -3.798870 | 0.009233 | 0.395320 | 0.374668 | -4.680470 | -3.767470 | -3.112510 | 2092.970 | 1201.110 | 1.000330 |
| logit_guess_group[1] | 0.073996 | 0.005242 | 0.249760 | 0.240632 | -0.408548 | 0.075708 | 0.576238 | 2271.090 | 1558.560 | 1.006470 |
| logit_guess_group[2] | -0.358434 | 0.005954 | 0.298411 | 0.308658 | -0.927045 | -0.359170 | 0.234254 | 2559.260 | 1405.850 | 1.003330 |
| logit_guess_group[3] | -0.893599 | 0.008853 | 0.386720 | 0.381542 | -1.662910 | -0.884521 | -0.134305 | 1955.850 | 1367.580 | 1.001680 |
| logit_slip_group[1] | -1.454010 | 0.005880 | 0.253594 | 0.244844 | -1.980090 | -1.448510 | -0.957734 | 1905.790 | 1533.050 | 1.001990 |
| logit_slip_group[2] | -2.259540 | 0.006370 | 0.287611 | 0.281694 | -2.854670 | -2.251620 | -1.730280 | 2159.370 | 1354.460 | 1.000970 |
| logit_slip_group[3] | -2.503820 | 0.006651 | 0.304977 | 0.290575 | -3.153980 | -2.475010 | -1.967660 | 2326.990 | 1208.900 | 1.001500 |
| pi_know[1] | 0.252838 | 0.002373 | 0.109792 | 0.112821 | 0.064220 | 0.246917 | 0.485576 | 1958.970 | 1067.480 | 1.002510 |
| pi_know[2] | 0.638896 | 0.002605 | 0.121326 | 0.129587 | 0.388218 | 0.645676 | 0.851357 | 2128.270 | 1473.040 | 0.999152 |
| pi_know[3] | 0.724938 | 0.002259 | 0.112757 | 0.107481 | 0.472677 | 0.734031 | 0.918922 | 2303.210 | 1122.930 | 1.001410 |
| learn[1] | 0.037740 | 0.000283 | 0.013327 | 0.012925 | 0.015894 | 0.036758 | 0.066822 | 2149.770 | 1240.310 | 0.999471 |
| learn[2] | 0.061239 | 0.000448 | 0.021269 | 0.020952 | 0.026254 | 0.058713 | 0.109362 | 2205.480 | 1401.090 | 1.003750 |
| learn[3] | 0.109103 | 0.000666 | 0.030232 | 0.029169 | 0.055679 | 0.107427 | 0.174243 | 2049.870 | 1156.790 | 1.001100 |
| forget[1] | 0.007198 | 0.000141 | 0.006578 | 0.005373 | 0.000044 | 0.005310 | 0.024836 | 1321.650 | 575.351 | 1.001810 |
| forget[2] | 0.033308 | 0.000209 | 0.010347 | 0.010119 | 0.016002 | 0.032461 | 0.056392 | 2410.380 | 1507.380 | 0.999805 |
| forget[3] | 0.023470 | 0.000182 | 0.008690 | 0.008185 | 0.009189 | 0.022588 | 0.042594 | 2093.100 | 1201.110 | 1.000330 |
| guess[1] | 0.259102 | 0.000645 | 0.030671 | 0.029930 | 0.199631 | 0.259459 | 0.320101 | 2271.060 | 1558.560 | 1.006450 |
| guess[2] | 0.206578 | 0.000706 | 0.035417 | 0.036829 | 0.141762 | 0.205580 | 0.279148 | 2559.340 | 1405.850 | 1.003210 |
| guess[3] | 0.148244 | 0.000900 | 0.039277 | 0.039619 | 0.079686 | 0.146121 | 0.233238 | 1955.870 | 1367.580 | 1.001490 |
| slip[1] | 0.096202 | 0.000450 | 0.019514 | 0.018577 | 0.060655 | 0.095115 | 0.138666 | 1905.790 | 1533.050 | 1.002140 |
| slip[2] | 0.048679 | 0.000269 | 0.012363 | 0.012165 | 0.027220 | 0.047605 | 0.075275 | 2159.430 | 1354.460 | 1.000900 |
| slip[3] | 0.039134 | 0.000215 | 0.010497 | 0.010506 | 0.020468 | 0.038814 | 0.061320 | 2326.940 | 1208.900 | 1.001970 |
Numba-based point-estimate predictions#
predict(...) and predict_smoothed(...) use Numba-compiled routines internally for fast inference with Bayesian point estimates for the parameters.
[12]:
from stanbkt.utils.data_utils import ColumnNames
col_mapping = {
ColumnNames.STUDENT_ID: "student_id",
ColumnNames.PROBLEM_ID: "problem_id",
ColumnNames.CORRECTNESS: "correct",
ColumnNames.ORDER: "timestamp",
ColumnNames.KC_ID: "kc_id",
ColumnNames.GROUP: "group_id",
}
[13]:
predictions = model.predict(
data_df,
column_mapping=col_mapping,
point_estimate="mean",
parallel=True,
fast_math=True,
)
predictions.head(20)
[13]:
| kc_id | student_id | problem_id | pKnow | pCorrectness | correct | |
|---|---|---|---|---|---|---|
| 0 | kc_1 | stu_0 | prob_0 | 0.072479 | 0.216648 | 0 |
| 1 | kc_1 | stu_0 | prob_2 | 0.079254 | 0.221594 | 0 |
| 2 | kc_1 | stu_0 | prob_6 | 0.080166 | 0.222260 | 0 |
| 3 | kc_1 | stu_0 | prob_7 | 0.080290 | 0.222350 | 1 |
| 4 | kc_1 | stu_0 | prob_8 | 0.368654 | 0.432900 | 1 |
| 5 | kc_1 | stu_0 | prob_10 | 0.774099 | 0.728935 | 0 |
| 6 | kc_1 | stu_0 | prob_12 | 0.350429 | 0.419592 | 0 |
| 7 | kc_1 | stu_0 | prob_17 | 0.129425 | 0.258227 | 0 |
| 8 | kc_1 | stu_0 | prob_19 | 0.087297 | 0.227467 | 0 |
| 9 | kc_1 | stu_0 | prob_20 | 0.081264 | 0.223061 | 0 |
| 10 | kc_1 | stu_0 | prob_22 | 0.080439 | 0.222459 | 0 |
| 11 | kc_1 | stu_0 | prob_24 | 0.080327 | 0.222377 | 0 |
| 12 | kc_1 | stu_0 | prob_25 | 0.080311 | 0.222366 | 0 |
| 13 | kc_1 | stu_0 | prob_33 | 0.080309 | 0.222365 | 0 |
| 14 | kc_1 | stu_0 | prob_37 | 0.080309 | 0.222364 | 1 |
| 15 | kc_1 | stu_0 | prob_40 | 0.368708 | 0.432938 | 0 |
| 16 | kc_1 | stu_0 | prob_44 | 0.133983 | 0.261555 | 0 |
| 17 | kc_1 | stu_0 | prob_50 | 0.087980 | 0.227965 | 0 |
| 18 | kc_1 | stu_0 | prob_51 | 0.081358 | 0.223130 | 0 |
| 19 | kc_1 | stu_0 | prob_59 | 0.080451 | 0.222468 | 0 |
[14]:
smoothed_predictions = model.predict_smoothed(
data_df,
column_mapping=col_mapping,
point_estimate="mean",
parallel=True,
fast_math=True,
)
smoothed_predictions.head(20)
[14]:
| kc_id | student_id | problem_id | pKnow | pCorrectness | correct | |
|---|---|---|---|---|---|---|
| 0 | kc_1 | stu_0 | prob_0 | 0.000107 | 0.163805 | 0 |
| 1 | kc_1 | stu_0 | prob_2 | 0.000427 | 0.164039 | 0 |
| 2 | kc_1 | stu_0 | prob_6 | 0.002743 | 0.165730 | 0 |
| 3 | kc_1 | stu_0 | prob_7 | 0.019798 | 0.178182 | 1 |
| 4 | kc_1 | stu_0 | prob_8 | 0.019798 | 0.178183 | 1 |
| 5 | kc_1 | stu_0 | prob_10 | 0.002748 | 0.165733 | 0 |
| 6 | kc_1 | stu_0 | prob_12 | 0.000434 | 0.164043 | 0 |
| 7 | kc_1 | stu_0 | prob_17 | 0.000120 | 0.163814 | 0 |
| 8 | kc_1 | stu_0 | prob_19 | 0.000077 | 0.163783 | 0 |
| 9 | kc_1 | stu_0 | prob_20 | 0.000071 | 0.163779 | 0 |
| 10 | kc_1 | stu_0 | prob_22 | 0.000071 | 0.163779 | 0 |
| 11 | kc_1 | stu_0 | prob_24 | 0.000078 | 0.163784 | 0 |
| 12 | kc_1 | stu_0 | prob_25 | 0.000124 | 0.163818 | 0 |
| 13 | kc_1 | stu_0 | prob_33 | 0.000469 | 0.164070 | 0 |
| 14 | kc_1 | stu_0 | prob_37 | 0.003011 | 0.165926 | 1 |
| 15 | kc_1 | stu_0 | prob_40 | 0.000469 | 0.164070 | 0 |
| 16 | kc_1 | stu_0 | prob_44 | 0.000124 | 0.163818 | 0 |
| 17 | kc_1 | stu_0 | prob_50 | 0.000078 | 0.163784 | 0 |
| 18 | kc_1 | stu_0 | prob_51 | 0.000071 | 0.163779 | 0 |
| 19 | kc_1 | stu_0 | prob_59 | 0.000070 | 0.163778 | 0 |
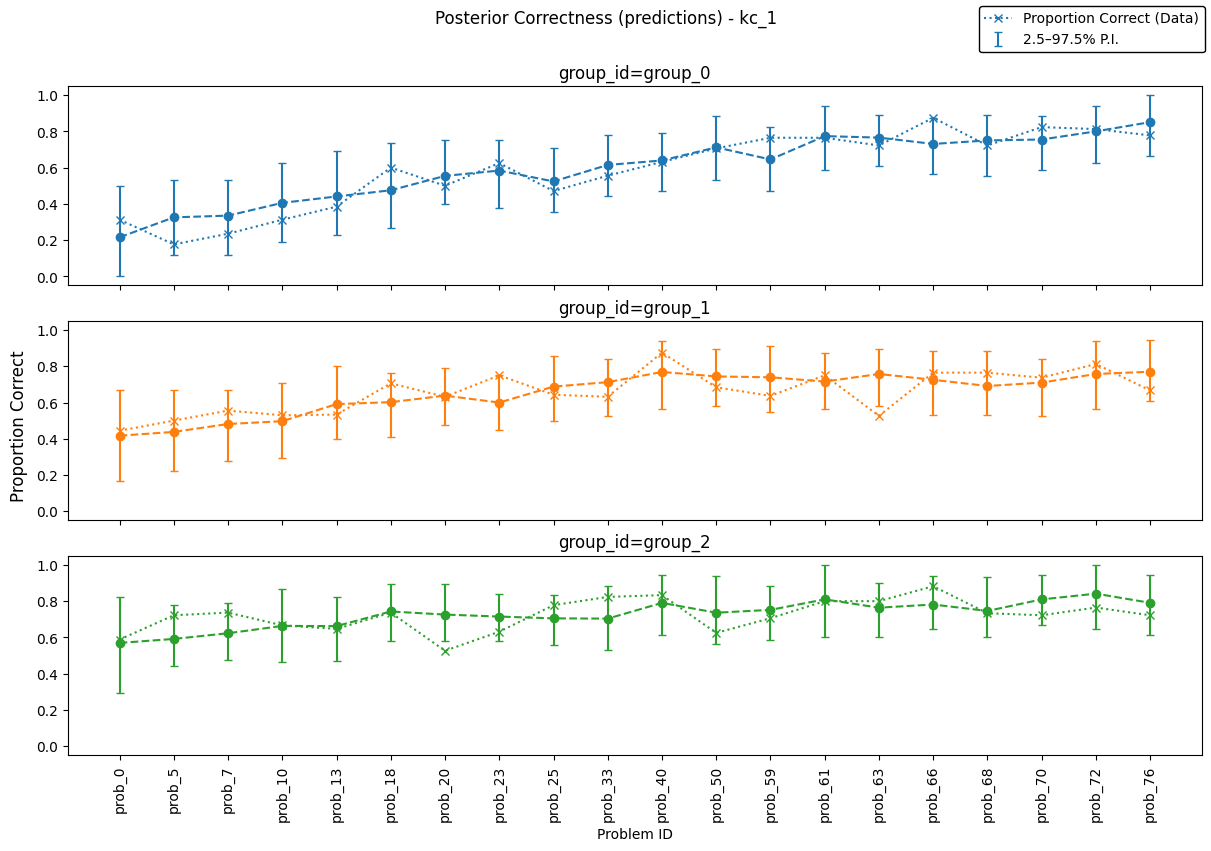
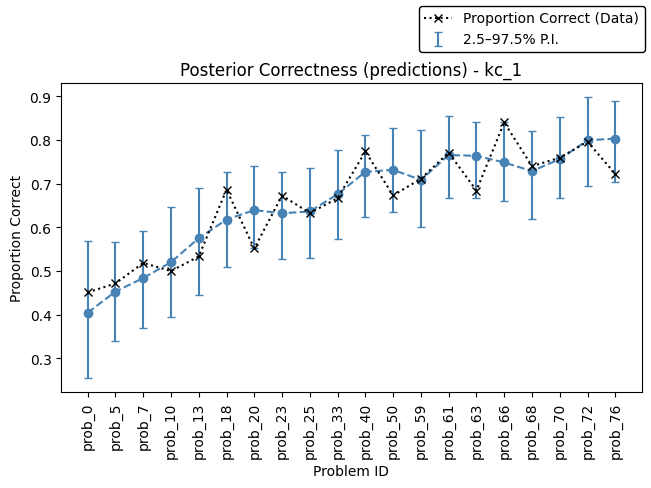
Predictions and Visualizations#
As MultiBKT estimates a separate set of parameters for each group, posterior correctness can be visualized in two ways.
By default, plot_posterior_correctness(...) aggregates across groups and produces a single panel for the selected KC. If you want to inspect how posterior correctness differs by group, pass grouped=True. In that mode, the function creates one subplot per group.
[15]:
pred_post_draws = model.predict_posterior_draws(data_df, column_mapping=col_mapping)
17:00:56 - cmdstanpy - INFO - Chain [1] start processing
17:00:56 - cmdstanpy - INFO - Chain [2] start processing
17:00:56 - cmdstanpy - INFO - Chain [3] start processing
17:00:56 - cmdstanpy - INFO - Chain [4] start processing
17:00:57 - cmdstanpy - INFO - Chain [1] done processing
17:00:57 - cmdstanpy - INFO - Chain [2] done processing
17:00:57 - cmdstanpy - INFO - Chain [4] done processing
17:00:57 - cmdstanpy - INFO - Chain [3] done processing
17:00:57 - cmdstanpy - INFO - Chain [1] start processing
17:00:57 - cmdstanpy - INFO - Chain [2] start processing
17:00:57 - cmdstanpy - INFO - Chain [3] start processing
17:00:57 - cmdstanpy - INFO - Chain [4] start processing
17:00:57 - cmdstanpy - INFO - Chain [1] done processing
17:00:57 - cmdstanpy - INFO - Chain [4] done processing
17:00:57 - cmdstanpy - INFO - Chain [3] done processing
17:00:57 - cmdstanpy - INFO - Chain [2] done processing
17:00:58 - cmdstanpy - WARNING - Sample doesn't contain draws from warmup iterations, rerun sampler with "save_warmup=True".
17:00:59 - cmdstanpy - WARNING - Sample doesn't contain draws from warmup iterations, rerun sampler with "save_warmup=True".
[ ]:
from stanbkt.plot import plot_posterior_correctness
# correctness predictions (with predictive intervals)
axes = plot_posterior_correctness(
posterior_pred_kc=pred_post_draws["kc_1"],
data=data_df,
column_mapping=col_mapping,
kc="kc_1",
type="preds",
trajectory=True,
frac=0.5,
)
[ ]:
axes_individual_groups = plot_posterior_correctness(
posterior_pred_kc=pred_post_draws["kc_1"],
data=data_df,
column_mapping=col_mapping,
kc="kc_1",
type="preds",
trajectory=True,
grouped=True,
frac=0.5,
)